
The Agentic Stack
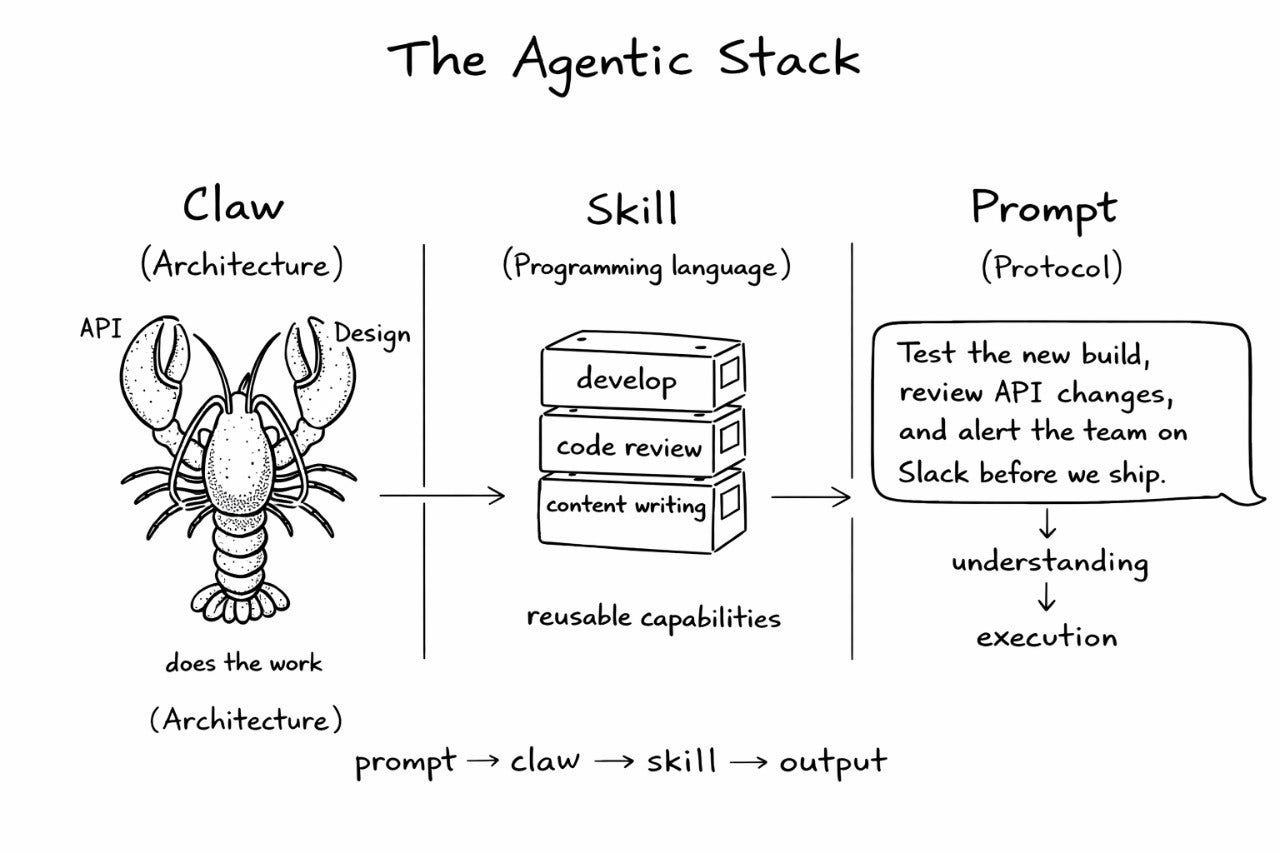
Claw is the architecture. Skill is the language. Prompt is the protocol.

We’ve spent years building software the same way. A service receives a request, calls another service, writes to a database. Something reads it back. You scale the slow parts, monitor the breaking ones.
That model still works. It’s reliable, well-understood, and well-tooled. But something’s shifted — and if you haven’t felt it yet in your architecture decisions, you will soon.
AI has introduced a new execution layer. Not infrastructure. Not middleware. Something that does work — the kind that used to require a human to sit down, think, and grind through.
The question nobody’s asking right now
Most leaders ask: “Should we use AI?” That’s the wrong level. Everyone’s already using it — in their IDE, their code review tool, their incident runbook.
Ask instead: What’s the architecture?
Because when AI stops being a feature and starts being an execution layer — something that does work rather than assists with work — your system’s structure changes. How you define capability changes. How intent enters the system changes. That’s what the agentic stack is about, and it’s worth understanding before your team figures it out without you.
Three layers. You already know all of them
Claw is the new unit of architecture. A bounded execution unit with its own role, context, tools, and constraints. Not a microservice — it doesn’t expose an API endpoint. It checks Slack, reads files, calls APIs, drafts responses, takes action. It does things.
Skill is the new programming language, an instruction layer. Reusable logic that tells a claw what to do, how to do it, what rules it’s operating under, and what good output looks like. If a claw is the executor, the skill is the judgment baked in.
Prompt is the communication protocol, how intent enters the system. Not a rigid API contract — a natural language instruction that activates claws and routes work through skills.
Three layers. Each one maps to something familiar.
What this replaces and what it doesn't
Here’s where most explanations go sideways: they frame this as replacement. It isn’t, and treating it that way will cause you to either over-invest or dismiss it entirely.
Services still define how systems run. Databases still store state. APIs still integrate third-party tools. None of that changes.
What changes is the coordination layer on top, the work that used to live in Notion docs, Jira comments, and Slack threads.
The glue work. The “someone needs to look at this and decide work”. Before the agentic stack, that required a human. After, a claw handles it.
Meet Priya
She’s a Senior Engineering Manager at a scaling platform team. Her week, pre-agentic stack: 15 PRs moving through review, senior engineers burning two to three hours a day reading diffs, junior engineers waiting three to five days for feedback that came back cryptic half the time anyway.
The process ran like this:
PR opened → Priya manually assigns reviewer based on who knows the area
Reviewer reads 300–500 lines of code
Leaves comments → author reads them, guesses at intent → revises
Reviewer re-reads, re-approves or re-requests changes
Repeat until it's good enough
That's six to eight human touchpoints per PR. Multiply by 15 PRs a week.
They tried building a claw to do first-pass reviews. The skill encoded the team’s standards — naming conventions, test coverage thresholds, security anti-patterns, documentation expectations. First two weeks were rough. It flagged too aggressively, left feedback in a tone that annoyed the engineers, and missed context on a few architectural decisions it didn’t have visibility into.
They fixed the skill. Rewrote the tone guidelines, added the architecture docs to its context, tuned the flagging thresholds. By week four, it was doing what a good junior reviewer would do — and Priya’s seniors were only seeing the PRs that genuinely needed a human call.
That’s the actual story. It wasn’t clean. It worked anyway.
What it looks like in practice
Here's a simplified skill definition for a code review claw:
name: code-review
role: Review pull requests against team engineering standards. Flag violations. Approve clean PRs. Escalate anything touching auth or payments.
context:
- repo: standards/engineering-guidelines.md
- file: .github/CODEOWNERS
tools:
- read_pr_diff
- post_review_comment
- request_human_review
- approve_pr
constraints:
- Never approve PRs touching /src/auth without human sign-off
- Always flag missing tests as blocking
- Post feedback in plain English, not just line references
output:
- structured review with verdict: approve | changes_requested | escalateThe skill is the logic. The claw is the executor. The PR opening is the prompt.
No new service to build. No new API to maintain. You're composing behaviour, not writing code.
What actually changes for you
Your senior engineers stop being the default reviewers. Their judgment gets encoded into skills — and applied at scale, consistently, without their calendar getting eaten. They shift from doing reviews to defining what a good review looks like. That’s a leverage upgrade.
Code standards become executable, not aspirational. There’s a meaningful difference between a policy nobody reads and a skill a claw runs on every PR. One is stated. One is applied. You’ve probably written a lot of policies that belong in the second category.
Your junior engineers get faster feedback loops. They learn faster because the signal isn’t filtered through whoever had time to review that week.
And you get visibility into work that was previously invisible. Every claw action is logged. Every decision is traceable. Which is a kind of accountability your process almost certainly doesn’t have right now.
How to start
Pick one workflow that is a bottleneck. Not a hypothetical one, a specific named workflow that your team complains about in retros.
Write down, in plain language, what a good human does in that workflow. Step by step. Including the judgment calls, the rules they apply, the things they'd escalate. That's your first skill. The trigger is your first prompt. The claw executes it.
Run it alongside your human process for two weeks. Don’t replace anything yet — just compare the outputs. Trust the parts that are right. Fix the parts that aren’t.
That’s it. Everything else is refinement.
The most interesting thing about this stack isn’t the technology. It’s that the judgment your best people carry around in their heads — the stuff that makes them irreplaceable — can now be encoded and applied everywhere, all the time, without them being in the room.
That’s what’s actually happening. The naming is new. The leverage isn’t.
What workflow in your team still requires a human because nobody’s written down what good looks like? Genuinely curious — drop it in the comments.